Today we will begin our exploration of the {dplyr} package! Our first verb on the list is select which allows to keep or drop variables from your dataframe. Choosing your variables is the first step in cleaning your data.
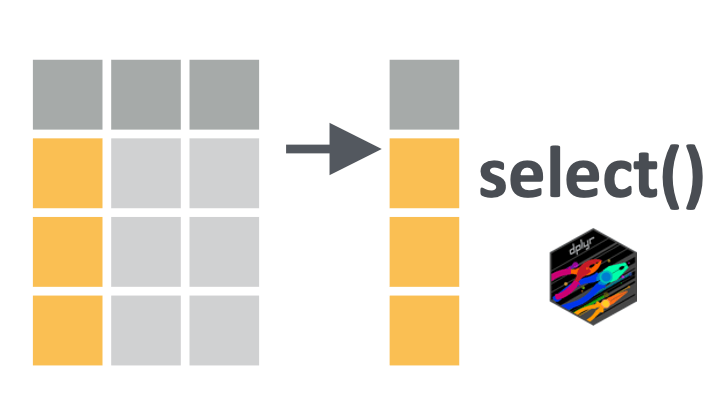
Fig: the select() function.
Let’s go !
9.2 Learning objectives
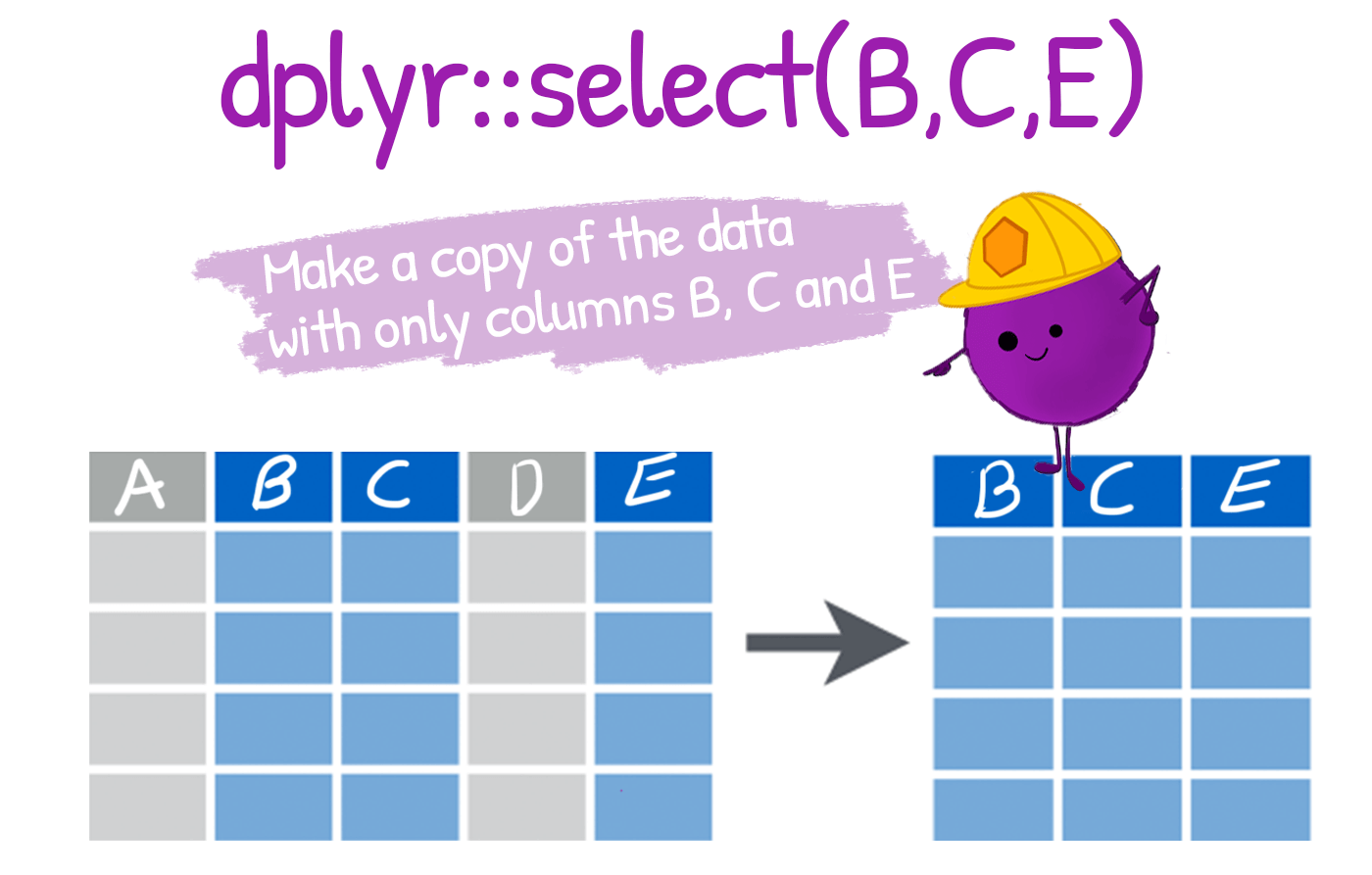
You can keep or drop columns from a dataframe using the dplyr::select() function from the {dplyr} package.
You can select a range or combination of columns using operators like the colon (:), the exclamation mark (!), and the c() function.
You can select columns based on patterns in their names with helper functions like starts_with(), ends_with(), contains(), and everything().
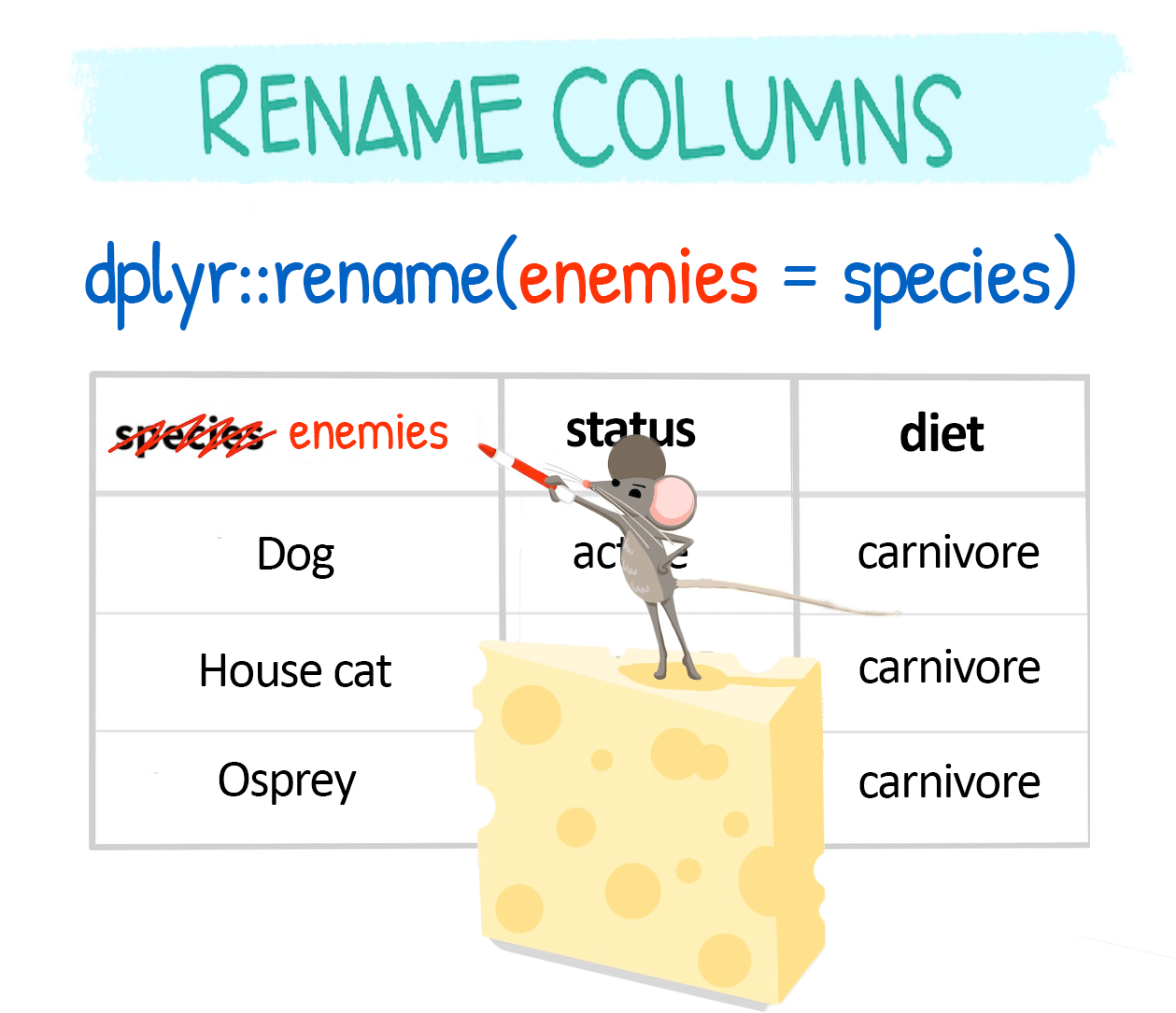
You can use rename() and select() to change column names.
9.3 The Yaounde COVID-19 dataset
In this lesson, we analyse results from a COVID-19 serological survey conducted in Yaounde, Cameroon in late 2020. The survey estimated how many people had been infected with COVID-19 in the region, by testing for IgG and IgM antibodies. The full dataset can be obtained from Zenodo, and the paper can be viewed here.
Spend some time browsing through this dataset. Each line corresponds to one patient surveyed. There are some demographic, socio-economic and COVID-related variables. The results of the IgG and IgM antibody tests are in the columns igg_result and igm_result.
# A tibble: 5 × 8
age sex highest_education occupation is_smoker is_pregnant igg_result
<dbl> <chr> <chr> <chr> <chr> <chr> <chr>
1 45 Female Secondary Informal work… Non-smok… No Negative
2 55 Male University Salaried work… Ex-smoker <NA> Positive
3 23 Male University Student Smoker <NA> Negative
4 20 Female Secondary Student Non-smok… No Positive
5 55 Female Primary Trader--Farmer Non-smok… No Positive
# ℹ 1 more variable: igm_result <chr>
9.4.1 Selecting column ranges with :
The : operator selects a range of consecutive variables:
yao %>%select(age:occupation) # Select all columns from `age` to `occupation`
# A tibble: 5 × 4
age sex highest_education occupation
<dbl> <chr> <chr> <chr>
1 45 Female Secondary Informal worker
2 55 Male University Salaried worker
3 23 Male University Student
4 20 Female Secondary Student
5 55 Female Primary Trader--Farmer
We can also specify a range with column numbers:
yao %>%select(1:4) # Select columns 1 to 4
# A tibble: 5 × 4
age sex highest_education occupation
<dbl> <chr> <chr> <chr>
1 45 Female Secondary Informal worker
2 55 Male University Salaried worker
3 23 Male University Student
4 20 Female Secondary Student
5 55 Female Primary Trader--Farmer
Practice
With the yaounde data frame, select the columns between symptoms and sequelae, inclusive. (“Inclusive” means you should also include symptoms and sequelae in the selection.)
9.4.2 Excluding columns with !
The exclamation point negates a selection:
yao %>%select(!age) # Select all columns except `age`
# A tibble: 5 × 7
sex highest_education occupation is_smoker is_pregnant igg_result igm_result
<chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 Fema… Secondary Informal … Non-smok… No Negative Negative
2 Male University Salaried … Ex-smoker <NA> Positive Negative
3 Male University Student Smoker <NA> Negative Negative
4 Fema… Secondary Student Non-smok… No Positive Negative
5 Fema… Primary Trader--F… Non-smok… No Positive Negative
To drop a range of consecutive columns, we use, for example,!age:occupation:
yao %>%select(!age:occupation) # Drop columns from `age` to `occupation`
# A tibble: 5 × 4
is_smoker is_pregnant igg_result igm_result
<chr> <chr> <chr> <chr>
1 Non-smoker No Negative Negative
2 Ex-smoker <NA> Positive Negative
3 Smoker <NA> Negative Negative
4 Non-smoker No Positive Negative
5 Non-smoker No Positive Negative
To drop several non-consecutive columns, place them inside !c():
yao %>%select(!c(age, sex, igg_result))
# A tibble: 5 × 5
highest_education occupation is_smoker is_pregnant igm_result
<chr> <chr> <chr> <chr> <chr>
1 Secondary Informal worker Non-smoker No Negative
2 University Salaried worker Ex-smoker <NA> Negative
3 University Student Smoker <NA> Negative
4 Secondary Student Non-smoker No Negative
5 Primary Trader--Farmer Non-smoker No Negative
Practice
From the yaounde data frame, remove all columns between highest_education and consultation, inclusive.
9.5 Helper functions for select()
dplyr has a number of helper functions to make selecting easier by using patterns from the column names. Let’s take a look at some of these.
9.5.1starts_with() and ends_with()
These two helpers work exactly as their names suggest!
yao %>%select(starts_with("is_")) # Columns that start with "is"
# A tibble: 5 × 2
is_smoker is_pregnant
<chr> <chr>
1 Non-smoker No
2 Ex-smoker <NA>
3 Smoker <NA>
4 Non-smoker No
5 Non-smoker No
yao %>%select(ends_with("_result")) # Columns that end with "result"
The fact that the new name comes first in the function (rename(NEWNAME = OLDNAME)) is sometimes confusing. You should get used to this with time.
9.6.1 Rename within select()
You can also rename columns while selecting them:
## Select `age` and `sex`, and rename them to `patient_age` and `patient_sex`yaounde %>%select(patient_age = age, patient_sex = sex)
# A tibble: 5 × 2
patient_age patient_sex
<dbl> <chr>
1 45 Female
2 55 Male
3 23 Male
4 20 Female
5 55 Female
9.7 Wrap up
I hope this first lesson has allowed you to see how intuitive and useful the {dplyr} verbs are! This is the first of a series of basic data wrangling verbs: see you in the next lesson to learn more.